
7/8 查找
7.1 查找的基本概念
查找表是由同一类型的数据元素(或记录)构成的集合。由于“集合”中的数据元素之间存在着松散的关系,因此查找表是一种应用灵便的结构。
**查找:**根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素或(记录)



7.2 线性表的查找
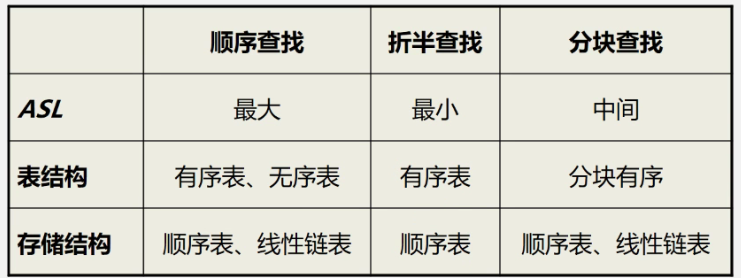
7.2.1 顺序查找



- 时间复杂度:O(n)
查找成功时的平均查找长度,设表中各记录查找概率相等ASL.(n)=(1+2+… +n)/n =(n+1)/2
空间复杂度:一个辅助空间——O(1); - 1、记录的查找概率不相等时如何提高查找效率?
查找表存储记录原则——按查找概率高低存储:
1)查找概率越高,比较次数越少;
2)查找概率越低,比较次数较多。
2、记录的查找概率无法测定时如何提高查找效率?
方法——按查找概率动态调整记录顺序:1)在每个记录中设一个访问频度域;
2)始终保持记录按非递增有序的次序排列;3)每次查找后均将刚查到的记录直接移至表头。
- 优点:算法简单,逻辑次序无要求,且不同存储结构均适用。
缺点:ASL太长,时间效率太低。
7.2.2 折半查找,二分查找


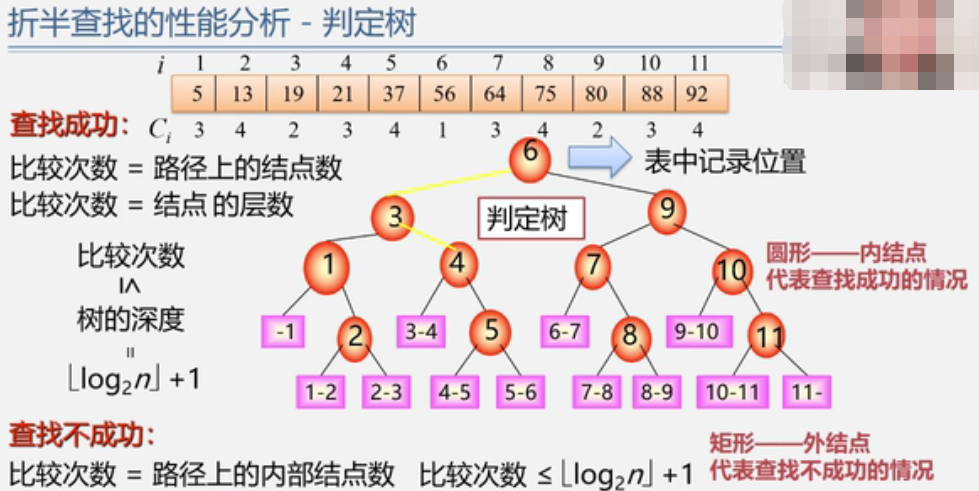

折半查找优点:效率比顺序查找高。O(log2 n)
折半查找缺点:只适用于有序表,且限于顺序存储结构(对线性链表无效)。
7.2.3 分块查找
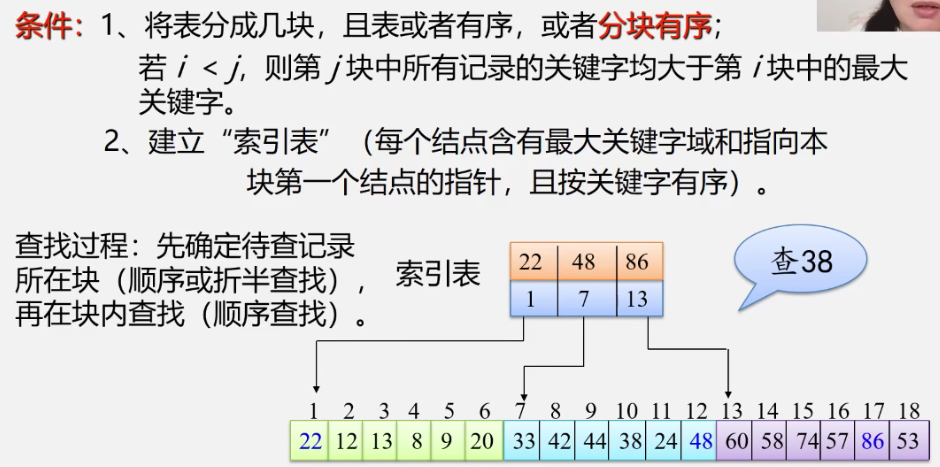
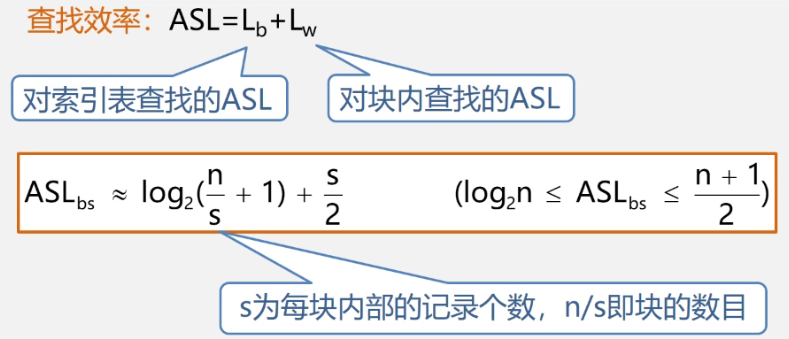
- 优点:插入和删除比较容易,无需进行大量移动。
缺点:要增加一个索引表的存储空间并对初始索引表进行排序运算。
适用情况:如果线性表既要快速查找又经常动态变化,则可采用分块查找。
7.3 树表的查找
7.3.1 二叉排序树
- 二叉排序树或是空树,或是满足如下性质的二叉树:
⑴)若其左子树非空,则左子树上所有结点的值均小于根结点的值;
(2若其右子树非空,则右子树上所有结点的值均大于等于根结点的值;
(3)其左右子树本身又各是一棵二叉排序树 - 中序遍历非空的二叉排序树所得到的数据元素序列是一个按关键字排列的递增有序序列。



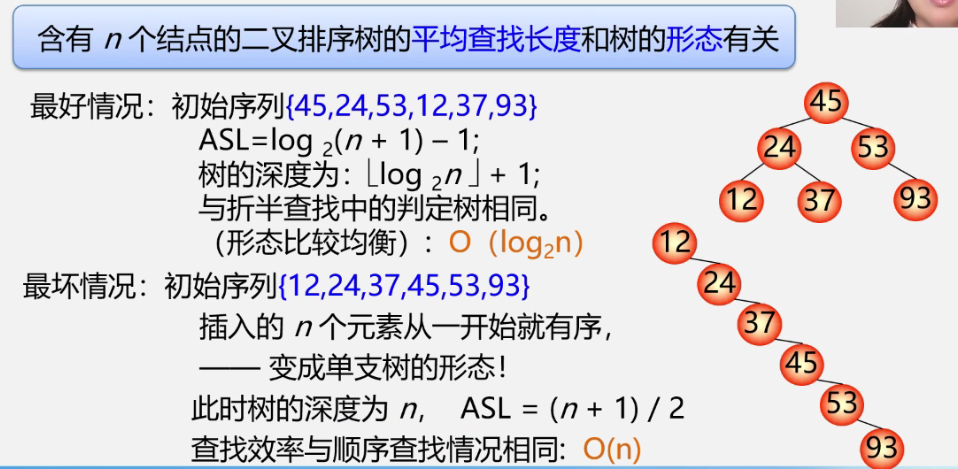

- 生成二叉排序树的算法,就是从根节点开始一个个做插入
- 不同插入次序的序列会生成不同形态的二叉排序树

1)被删除的结点是叶子节点:直接删去该结点
2)被删除的结点只有左子树或者只有右子树,用其左子树或者右子树替换它(结点替换)。
3)被删除的结点既有左子树,也有右子树:
以其中序前趋值替换之,然后再删除该前趋结点。前趋是左子树中最大的结点。
也可以用其后继替换之,然后再删除该后继结点。后继是右子树中最小的结点。
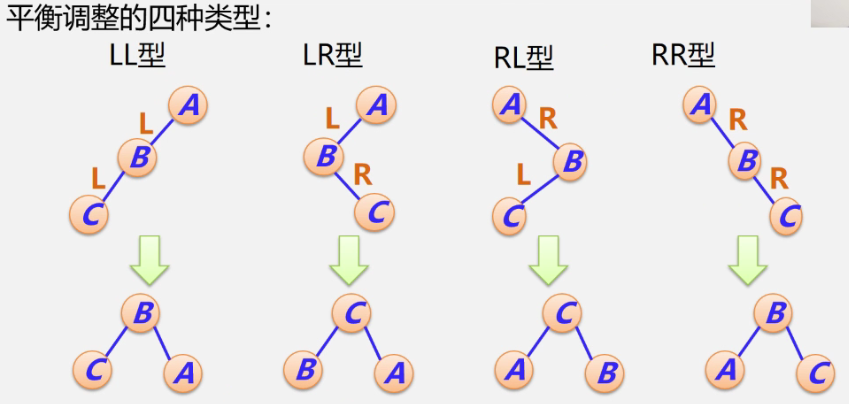
7.3.2 平衡二叉树
问题:如何提高形态不均衡的二叉排序树的查找效率?
解决办法:做“平衡化”处理,即尽量让二叉树的形状均衡!

为了方便起见,给每个结点附加一个数字,给出该结点左子树与右子树的高度差。这个数字称为结点的平衡因子(BF)。
平衡因子=结点左子树的高度–结点右子树的高度
根据平衡二叉树的定义,平衡二叉树上所有结点的平衡因子只能是-1、0,或1。
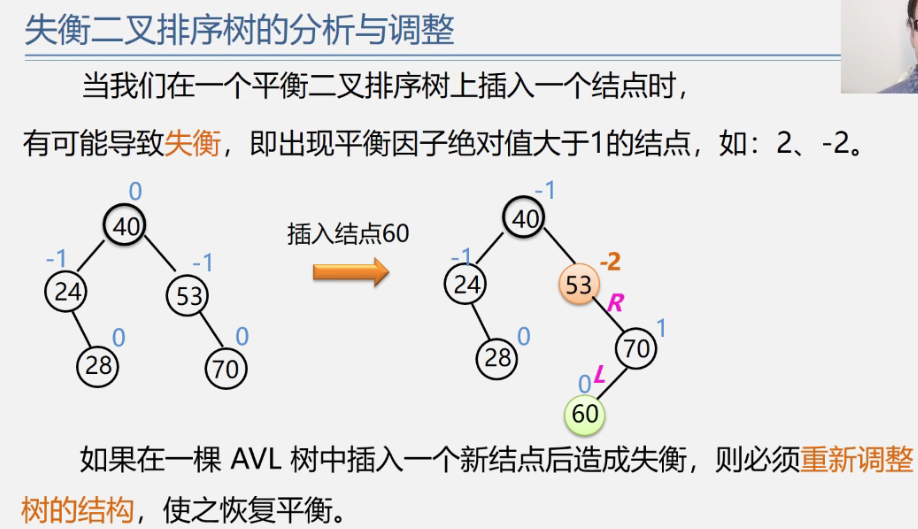
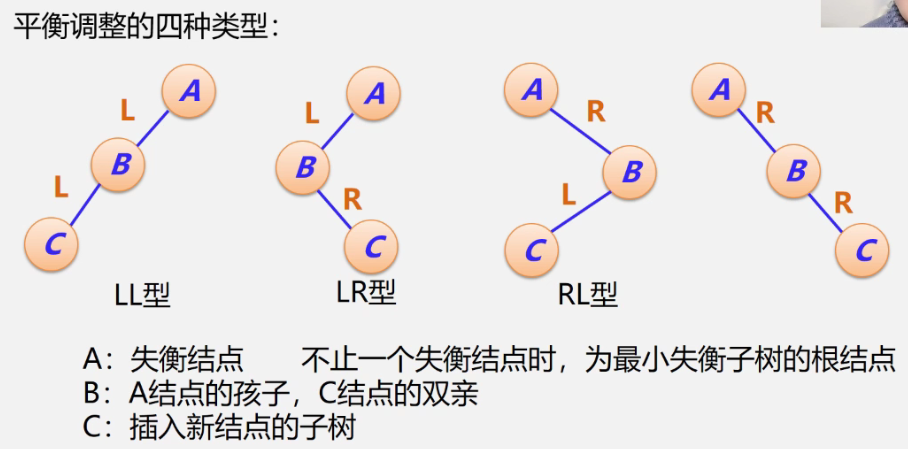
调整原则:降低高度+保持二叉树的性质
7.4 散列表的查找:牺牲空间换时间
7.4.1 基本概念
关键字与存储的位置存在某种对应关系
- 散列方法(杂凑法)
选取某个函数,依该函数按关键字计算元素的存储位置,并按此存放;查找时,由同一个函数对给定值k计算地址,将k与地址单元中元素关键码进行比,确定查找是否成功。 - 散列函数(杂凑函数):散列方法中使用的转换函数,散列表就是按照上述思想构造的表



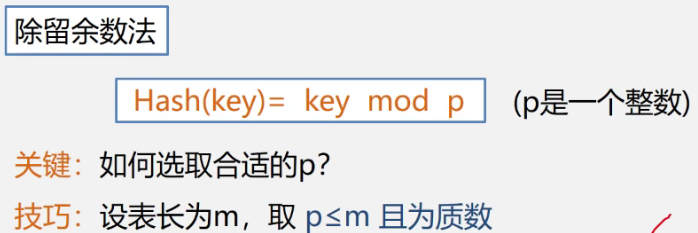
7.4.2 解决冲突





7.4.3 散列表的查找
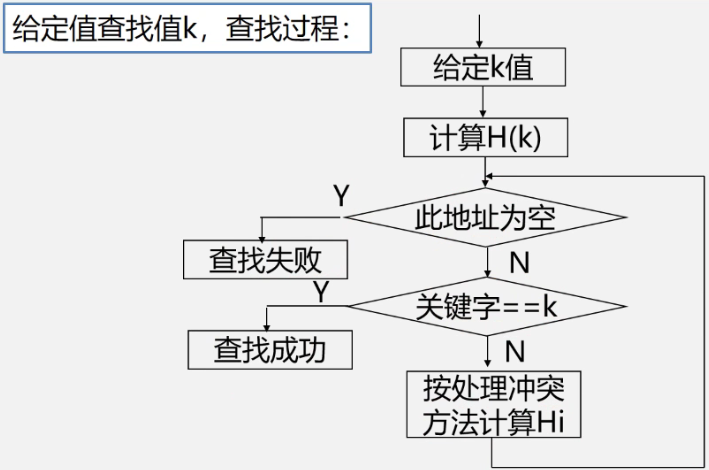


- 一些结论:
散列表技术具有很好的平均性能,优于一些传统的技术
链地址法优于开地址法
除留余数法作散列函数优于其它类型函数
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 ClancyCC!
评论

